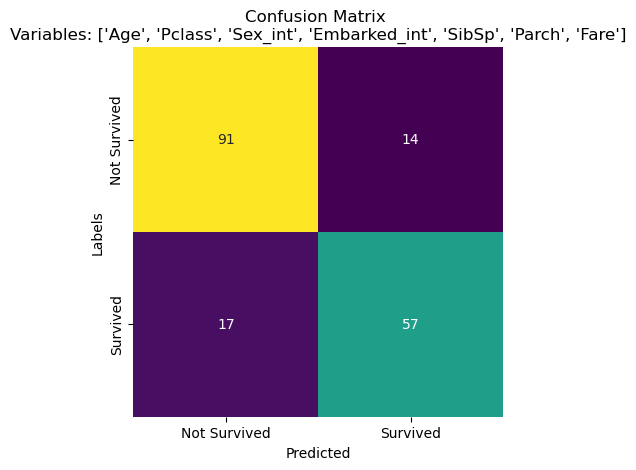
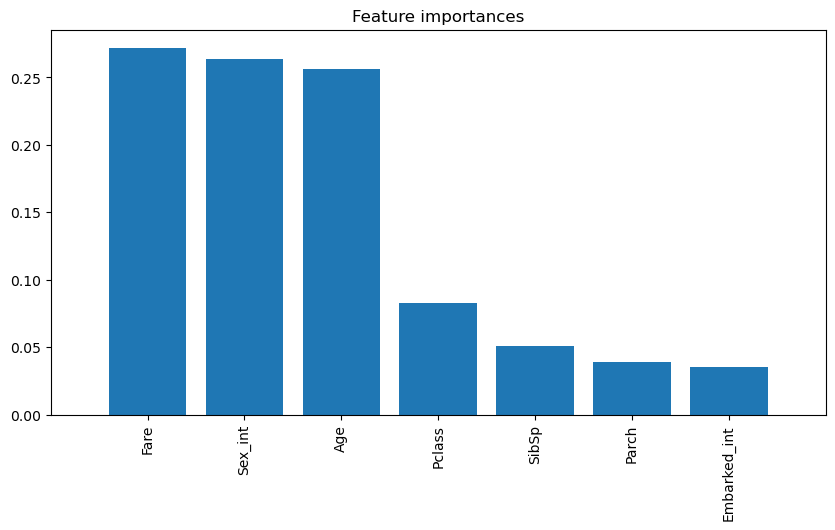
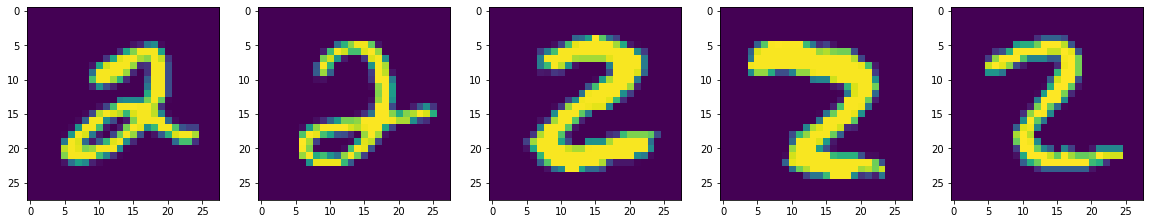we’ve gotten pretty good results using the existing features in the dataset. But we can create new features using the existing ones, and thay may help us improve accuracy.
The “Name” variabel contains the names of the passengers, including their titles:
df['Name'].head()
0 Braund, Mr. Owen Harris
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
2 Heikkinen, Miss. Laina
3 Futrelle, Mrs. Jacques Heath (Lily May Peel)
4 Allen, Mr. William Henry
Name: Name, dtype: object
From the names, we can identify Doctors, military officers, married and unmarried women, reverends, and more. Use natural language processing to create a new column with a value of 0 or 1 if an individual pertains to any of these classes. Add these new features to your model and see if they help us more accurately predict survival.
Optional: visuialize the random forest
from sklearn.tree import export_graphvizimport pydotplusfrom IPython.display import Imageestimator = rf.estimators_[0]# Export the tree to a dot filedot_data = export_graphviz(estimator, out_file=None, feature_names=X.columns, class_names=['Not Survived', 'Survived'], filled=True, rounded=True, proportion=True, special_characters=True) # Use pydotplus to create a graph from the dot datagraph = pydotplus.graph_from_dot_data(dot_data) # Display the treeImage(graph.create_png())
Deep Learning
The following goes above and beyond what we’ve learned in this class, but offers a window into the sorts of things you would learn if you chose to continue down the path of quantitative analysis. We will:
Load a prebuilt dataset.
Build a neural network machine learning model that classifies images.
Train this neural network.
Evaluate the accuracy of the model.
Set up TensorFlow
Import TensorFlow into your program to get started:
import numpy as npimport tensorflow as tfimport matplotlib.pyplot as plt#print("TensorFlow version:", tf.__version__)
If you are following along in your own development environment, rather than Colab, see the install guide for setting up TensorFlow for development.
Note: Make sure you have upgraded to the latest pip to install the TensorFlow 2 package if you are using your own development environment. See the install guide for details.
Load a dataset
Load and prepare the MNIST dataset. Convert the sample data from integers to floating-point numbers:
Note: It is possible to bake the tf.nn.softmax function into the activation function for the last layer of the network. While this can make the model output more directly interpretable, this approach is discouraged as it’s impossible to provide an exact and numerically stable loss calculation for all models when using a softmax output.
Define a loss function for training using losses.SparseCategoricalCrossentropy, which takes a vector of logits and a True index and returns a scalar loss for each example.
This loss is equal to the negative log probability of the true class: The loss is zero if the model is sure of the correct class.
This untrained model gives probabilities close to random (1/10 for each class), so the initial loss should be close to -tf.math.log(1/10) ~= 2.3.
loss_fn(y_train[:1], predictions).numpy()
3.2523074
Before you start training, configure and compile the model using Keras Model.compile. Set the optimizer class to adam, set the loss to the loss_fn function you defined earlier, and specify a metric to be evaluated for the model by setting the metrics parameter to accuracy.
Congratulations! You have trained a machine learning model using a prebuilt dataset using the Keras API.
For more examples of using Keras, check out the tutorials. To learn more about building models with Keras, read the guides. If you want learn more about loading and preparing data, see the tutorials on image data loading or CSV data loading.